
问题
生产中,随着扫码相关提供的服务大量接入,高并发为服务带来了不稳定性,主要体现在机器状态很差 CPU经常飙高至1500%以上.
解决方案
第一次优化
生产CPU飙高,我们可以猜测主要是因为俩个方向影响:
1、大量计算在消耗CPU
2、大量线程和程序上下文频繁切换导致拖累CPU
问题一开始,我是定位到了第二个点,因为我根本没考虑大量计算会消耗,这也是问题分析比较不好的习惯,以己度人。我用自己可能常见的分析去揣测,这是比较傻的行为。
对于一开始认为的第二个点,主要优化了Tomcat的一些参数,对于连接数和线程池的分析,参考了文章。【1】 然后有了如下的大致估计量和参数
1 | # Tomcat |
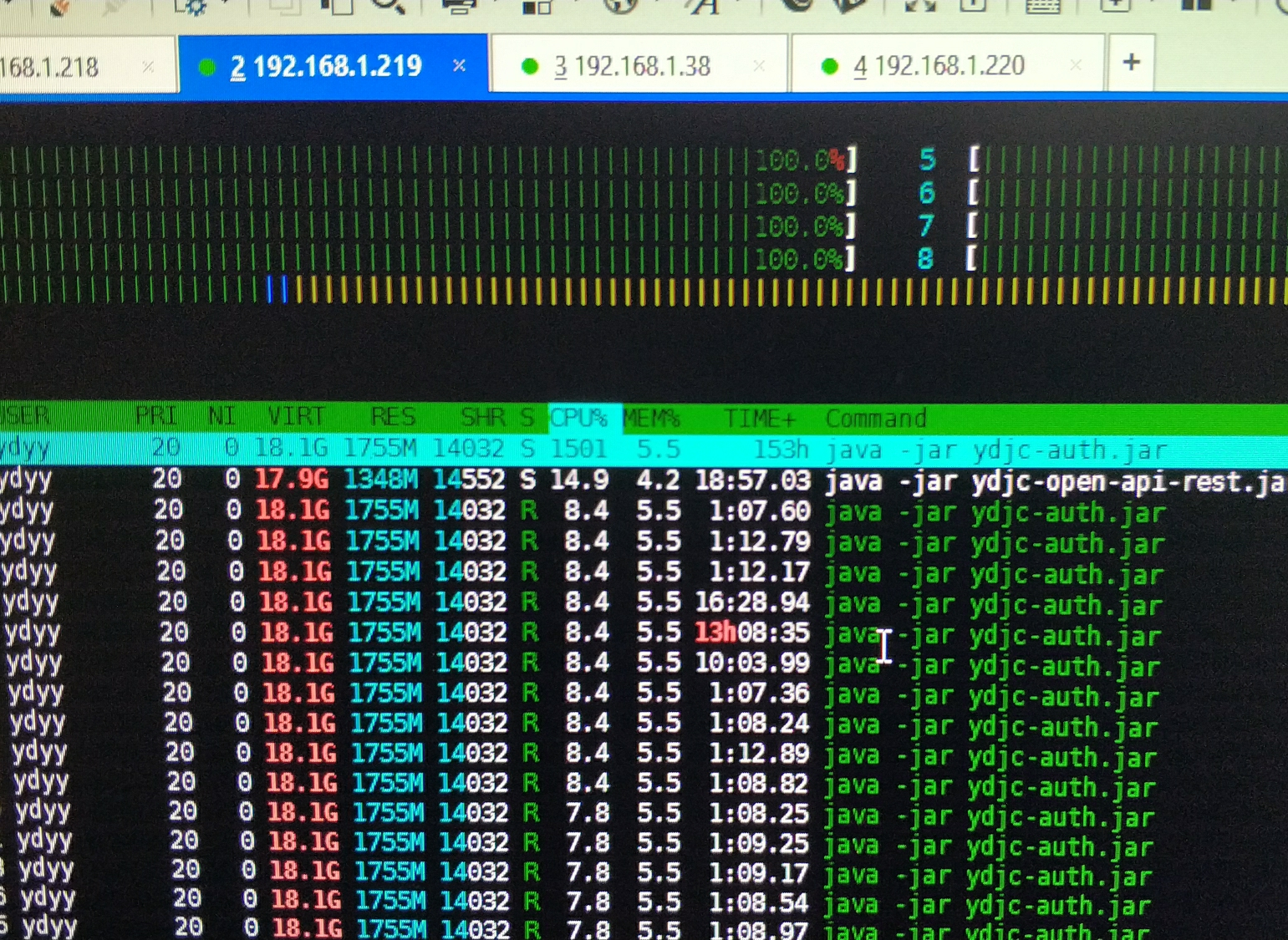
第一次优化后,有了如下的效果。大致下降到800%左右的。但任然是超高的负载。
其实对于后面模拟测试也可以发现,线程的数量取舍也比较重要,模拟下来大多都是block的线程而且内存cpu都呈锯齿状,可以说明资源短时间内其实是过剩的
所以第一次的数值是具有问题的,没有摸清性能拐点在哪里。
第二次优化
在苏彭的帮助下,详细了解了tomcat一些线程的参数。上面所示的参数对于单个节点来说,负载相当大
1 | #最大链接数 |
尤其这俩个参数的设置,会把线程等待拉到很高的值。相对于CPU就是很高负载。
所以稍微调整一下参数,一个对于单个节点相对合理的参数(因为鉴权这个服务本身就是高并发的,所以最小线程我们也调整的很高,对于慢热的那种系统,建议此数值适量调低)
1 | # Tomcat |
服务代码中也优化了一处,有个作为常量的HashMap,也修改为了ConcurrentHashMap
对于HashMap在高并发在发生死循环CPU飙高,可以查看详细介绍【1】
至此,每个节点忙时峰值CPU大概下降到300%
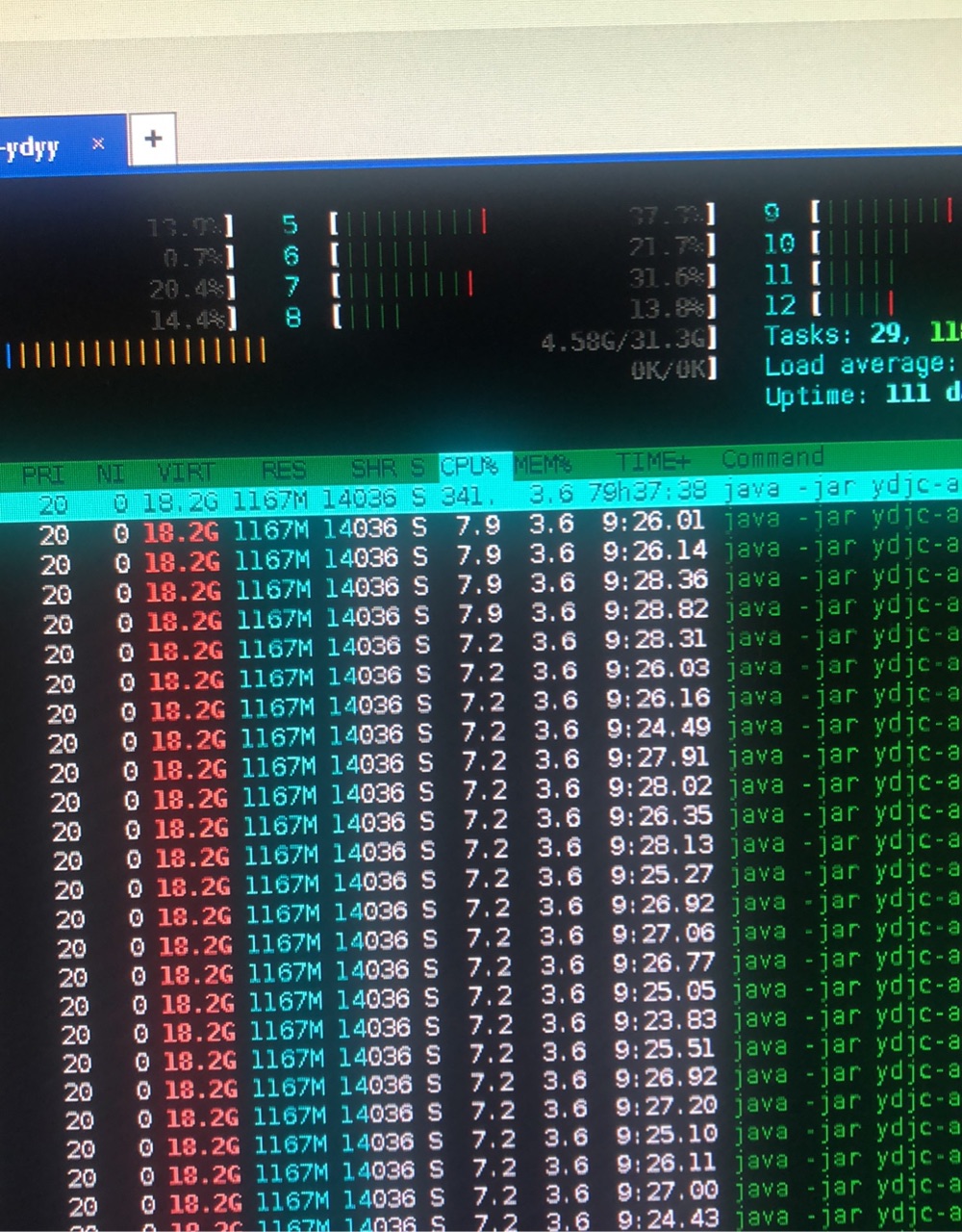
如果线程频繁切换和可能出现的死锁问题都解决了,CPU仍然稍高,可能就是真的存在密集计算的问题了,所以有了第三次优化的过程。
第三次优化
第三次优化才是真正解决问题的时候,虽然已经勉强满足了正常忙时机器状态。
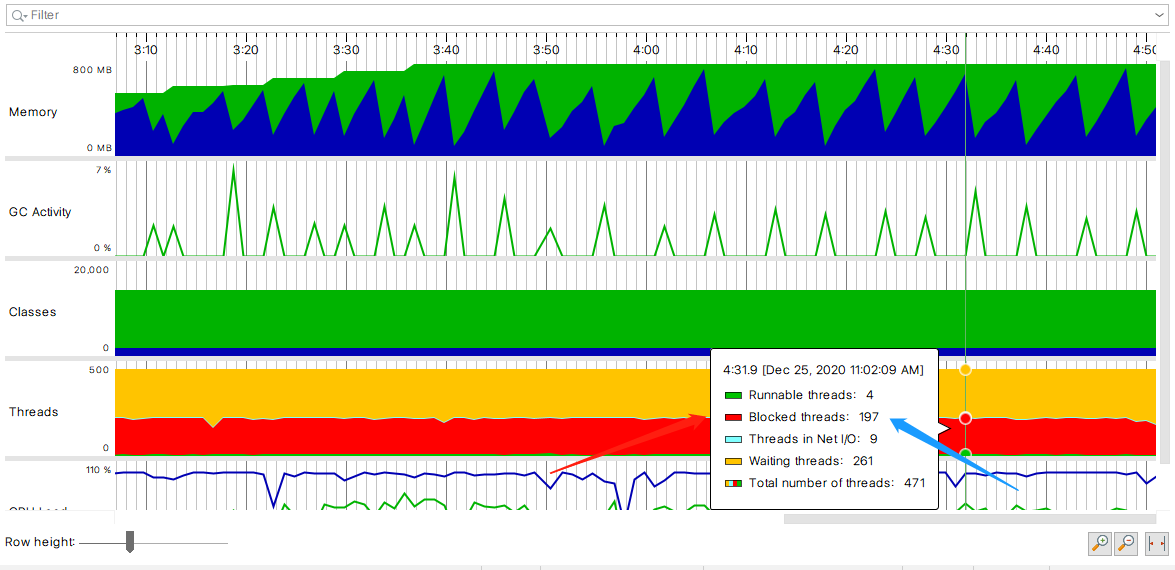
然后拜托运维拿到了鉴权服务忙时的jstack和jconsole一些基本数据
分析后发现,内存稳定,新老代也稳定,基本上确定是大量计算而不存在线程切换和死锁问题了
随后定位到如下RUNNABLE的一个线程。显示BCrypt算法一直在拖累系统。
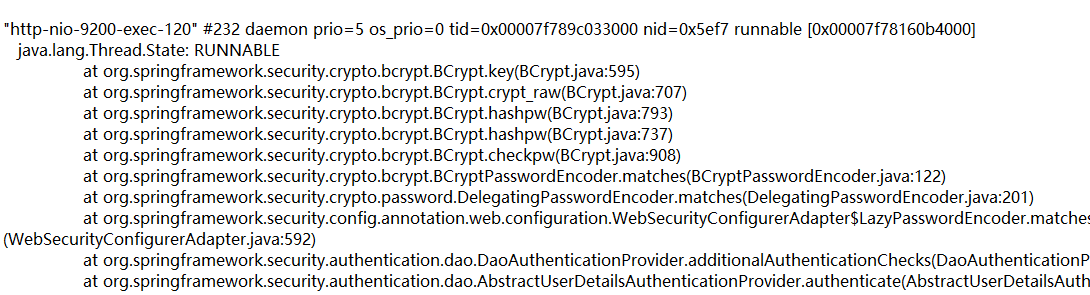
随后看了一下block的线程
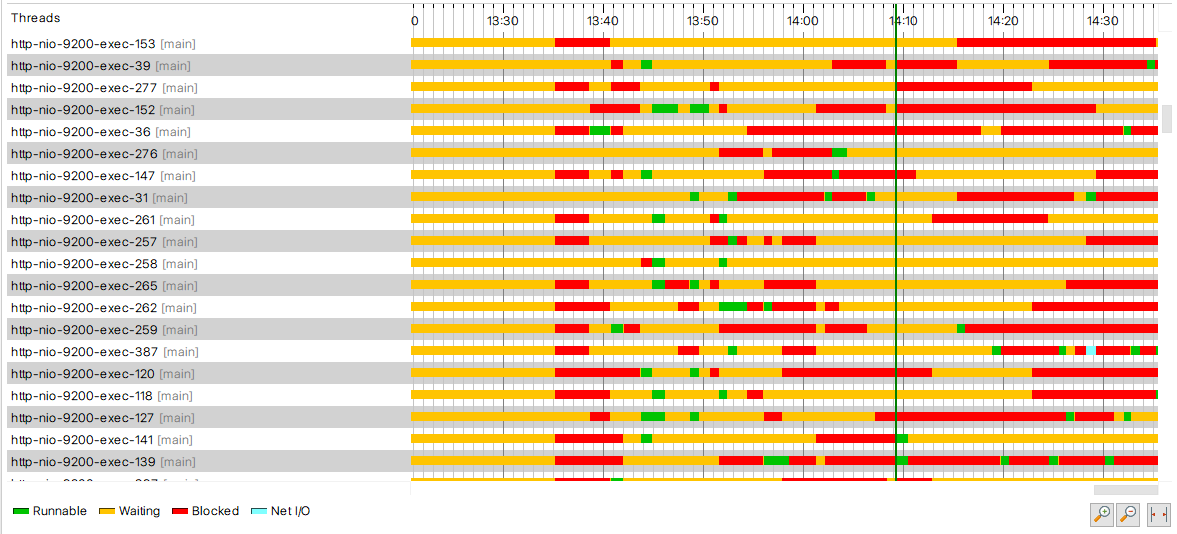
再从calltree中查询一下

可以看到确实存在密集计算的影子
查了一下资料【2】发现Bcrypt算法还真的是x86 cpu还有arm cpu的密集运算
算法保证了很高的安全性,是非常强的Hash算法,为了高安全刻意设计的如此消耗cpu的一个强散列算法。。。所以用这种算法保证鉴权的一些服务肯定是需要考量一下安全和性能的平衡。
在做过一系列压测和调研后,设计将一些内部的服务间访问,还有局域网内系统间访问的都修改为MD4这种弱Hash,对于暴露外部系统的继续使用Bcrypt强Hash。
具体的切换过程,可以参考shardingsphere脱敏的流程。
还有一个技巧是可以通过nacos权重来测试一下生产改变后的负载状态是否满足需要
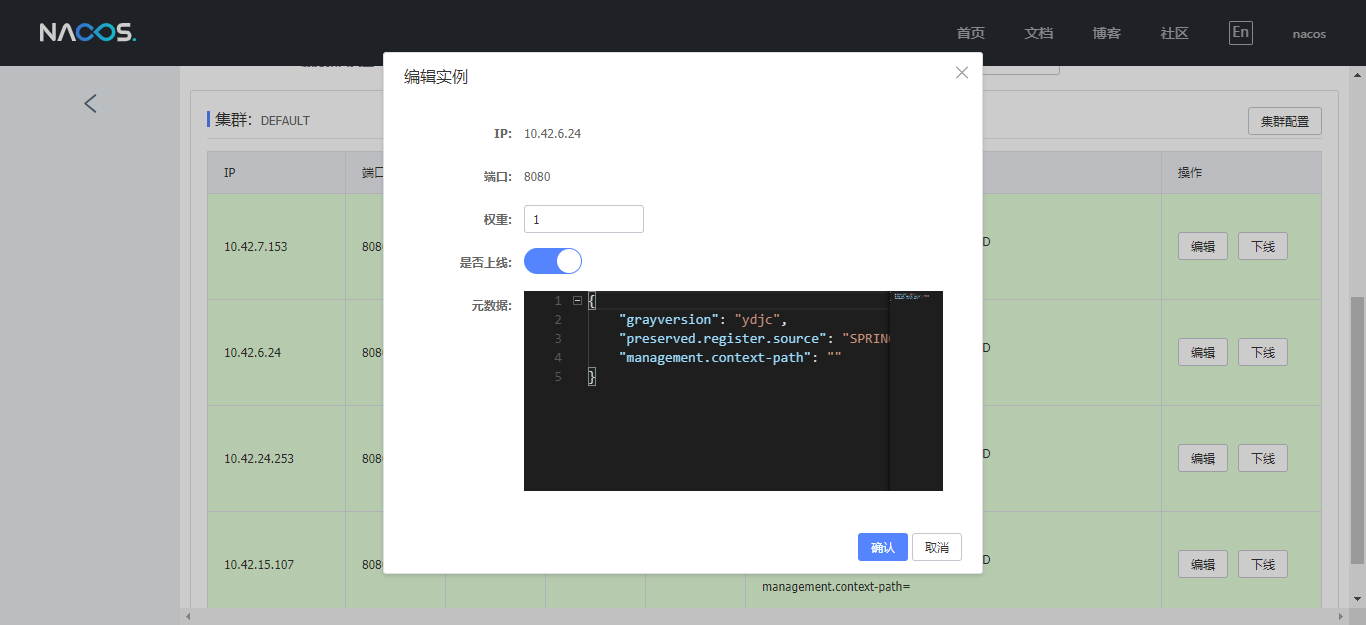
调整后,每个节点CPU均已正常。
对于生产故障的思考
- 首先从发生到完全解决 我用了三天,对于生产个人认为最快的响应才是最重要的。解决问题可能根据个人能力有快有慢,这个时候最快的响应比如说“增加节点” 相信可能是最好的方式。
- 对于故障问题,切记不能以己度人。多分析,多思考。
- 对于降级服务,可以通过Mock对象方式来补偿。
- 感谢帮助过的人:
