
消息中间件出现的场景:BOSS中心和CRM中心存在不同的数据库,一些诸如停开机用户数据同步和缴费数据同步的过程以前老系统是使用应用集成平台扫描表做数据搬运的动作。搬运过程中对数据库的压力和IO的压力都很大,处理效率低并且对传输过程中丢失的数据无法追踪,无重试和保证机制。在这个需求下,将使用到同步的场景采用消息中间件来触发。
具体流程是:将需要同步的主题和数据从对象池中取出,没有的话就新建一个,但主题保证是已有的。通过NIO将消息主体等内容发送到消息中间件,并对数据做个存储(Mysql集群存,主备相互备份)数据库的建模按照一个主题来建表,队列分区建表有点浪费资源,消息中间件根据主题发送到相应的主机上去处理,如果因为任何原因失败了,将重试三次,三次后仍失败将消息状态置为失败。
消息发送到相应主机后,存储到消息接口表中,根据进程扫描本地接口表做同步处理。处理成功后反馈给消息中间件,然后再发送消息给生产者告知。至此消息处理完毕。(ACK过程,第一次发送是SEND状态,第二次发送是COMMIT状态,全部状态都得到反馈,消息发送成功)
可以说说消息中间件使用的几点技术:
1.整体消息中间件系统参考
这个是一个真实生产化的消息系统案例,由 1 个架构师 +2 个高级工程师设计开发,第一期研发测试到上生产约 3 个月,目前该系统日处理消息量过亿。
假定公司因为业务需要,要构建一套分布式消息系统 MQ,类似 Kafka 这样的,这个问题看起来很大很复杂,但是如果你抽丝剥茧,透过现象看本质,Kafka 这样的消息系统本质上是下图这样的抽象概念: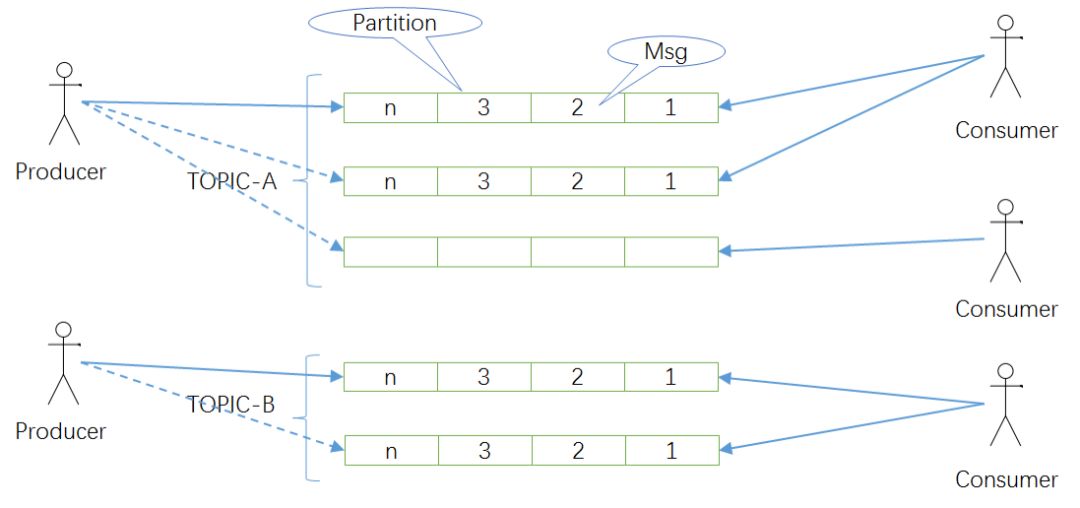
- 队列其实就是类似数组一样的结构(用数组建模有个好处,有索引可以重复消费),里头存放消息 (Msg),数组一头进消息,一头出消息;
- 左边是若干生产者 (Producer),往队列里头发消息;
- 右边是若干消费者 (Consumer),从队列里头消费消息;
- 对于生产者和消费者来说,他们不关心队列实现细节,所以给队列一个更抽象的名字,叫主题 (Topic);
- 考虑到系统的扩容和分布式能力,一般一个主题由若干个队列组成,这些队列也叫分区 (Partition),而且这些队列可能还是分布在不同机器上的,例如下图中 Topic A 的两个队列分布在 DataNode1 节点上,另外两个队列分布在 DataNode2 节点上,这样以后 Topic 可以按需扩容,DataNode 也可以按需增加。当然这些细节由 MQ 系统屏蔽,用户只关心主题,不关心底层实现。
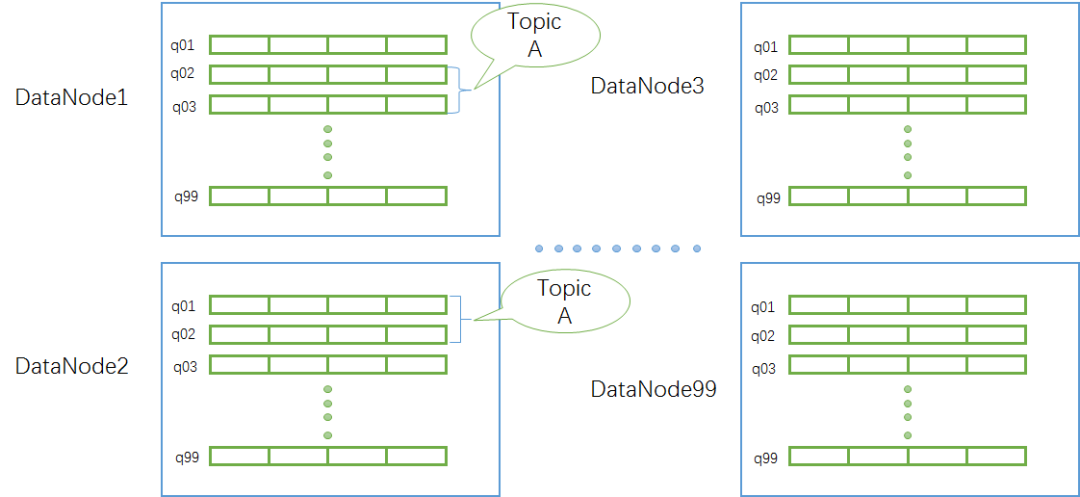
单个数组队列的建模是整个 MQ 系统的关键,我们知道 Kafka 使用 append only file 建模队列,存取速度快。假设我们要存业务数据需要更高可靠性,也可以用数据库表来建模数组队列,如下图所示: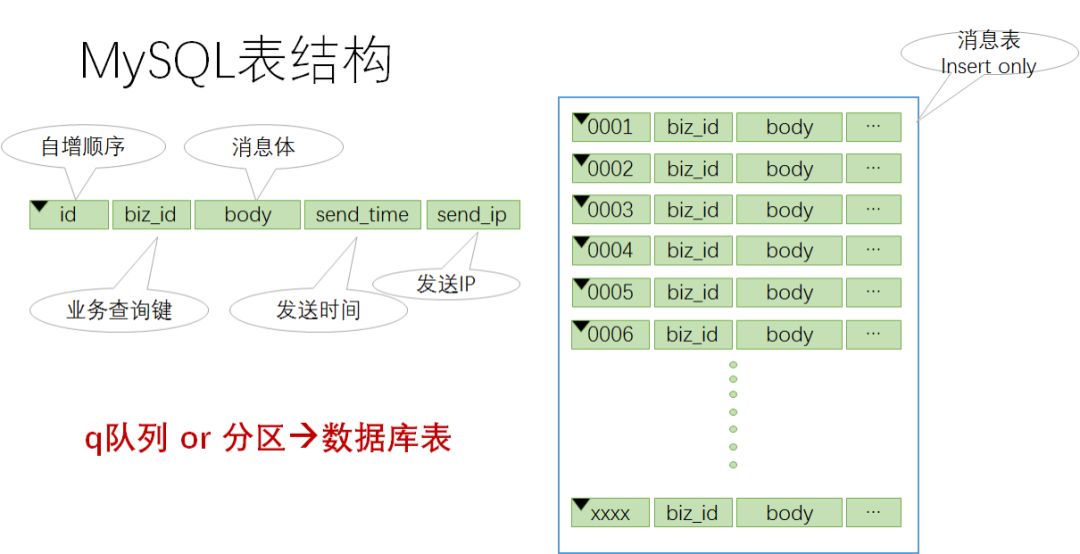
一个队列 (或者一个分区) 对应一张数据库表,表中的一个记录就是一条消息,表采用自增 id,相当于数组索引。这张表是 insert only 的,且 MySQL 会自动对自增 id 建优化索引,没有其它索引,所以插入和按 id 查找速度都非常快。
下面是总体元数据模型: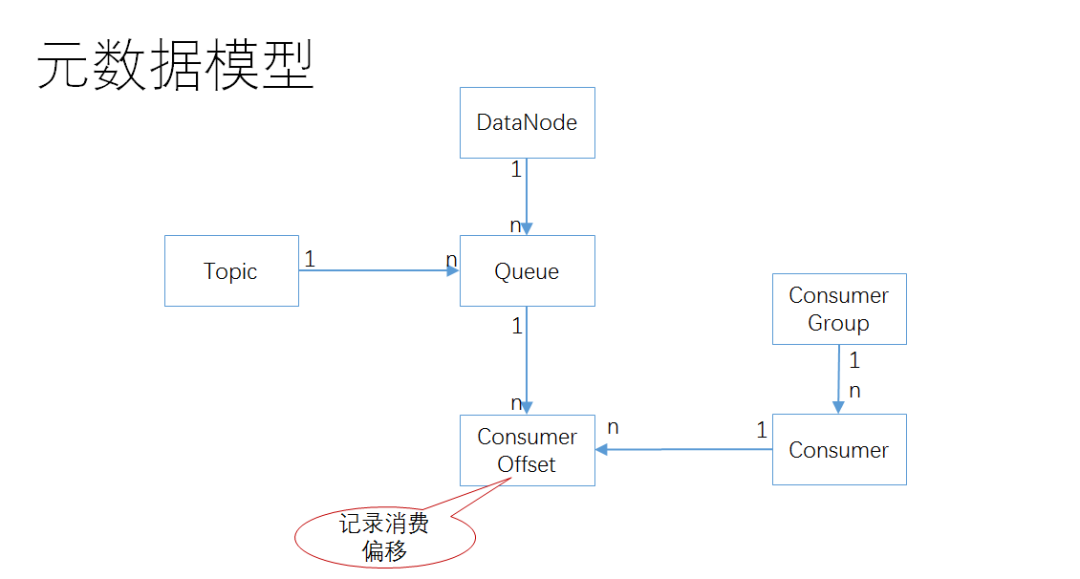
一个主题 Topic 对应若干个队列 Queue
一个数据节点 DataNode 上可以住若干个队列 Queue
消费者 Consumer 和队列 Queue 之间是多对多关系,通过消费者偏移 Consumer Offset 进行关联
一个消费者组 Consumer Group 里头有若干个消费者 Consumer,它们共同消费同一个主题 Topic
至此,我们对 MQ 的抽象建模工作完成,下面的工作是将这个模型映射到具体实现,经过分解,整个系统由若干个子模块组成,每个子模块实现后拼装起来的 MQ 总体架构如下图所示: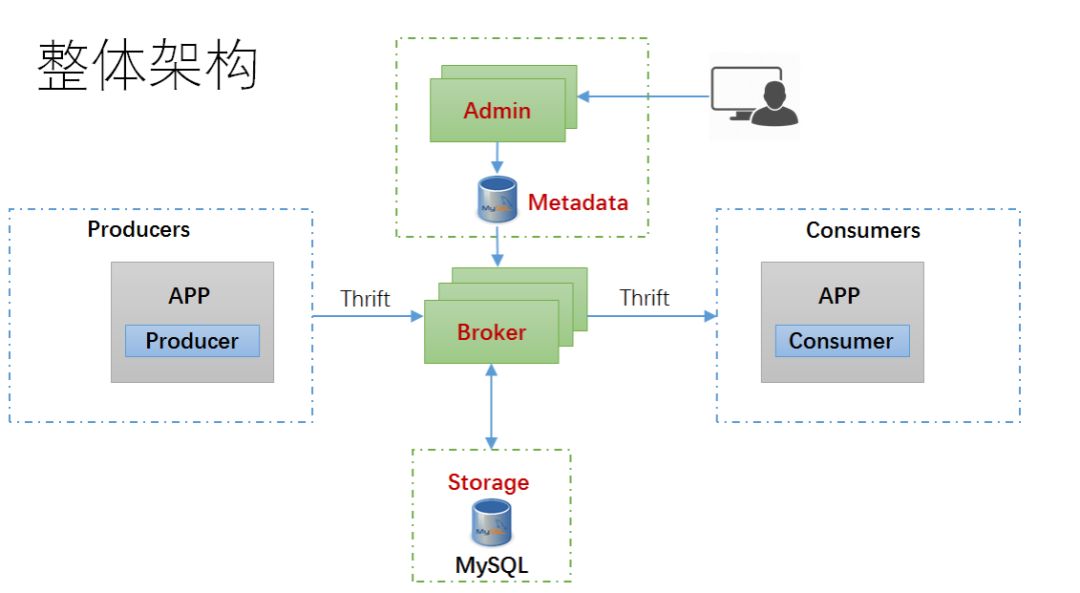
Admin 模块管理数据库节点,生产者,消费者 (组),主题,队列,消费偏移等元数据信息。
Broker 模块定期从 Admin 数据库同步元数据,接受生产者消息,按路由规则将消息存入对应的数据库表 (队列) 中;同时接受消费者请求,根据元数据从对应数据库表读取消息并发回消费者端。Broker 模块也接受消费者定期提交消费偏移。
Producer 接受应用发送消息请求,将消息发送到 Broker;
Consumer 从 Broker 拉取消息,供上层应用进一步消费;
客户端和 Broker 之间走 Thrift over HTTP 协议,中间通过域名走 Nginx 代理转发;
这个设计 Broker 是无状态,易于扩展。
架构思维总结:
整个架构设计的思路体现了先总体抽象,再分解按模块抽象并实现,最后组合成完整的 MQ 系统,也就是 抽象 + 分治。这个 MQ 的实现工作量并不大,属于小型系统范畴,初期设计和开发由 1 个架构师 +2 个中高级工程师可以搞定。
在初期研发和上生产之后,根据用户的不断反馈,系统设计经过多次优化和调整,符合三分架构、七分演化的 演化式架构 理念。目前该系统已经进入 V2 版本的架构和研发,其架构仍在持续演化当中,用户需求的多样性和对系统灵活性的更高要求,是系统架构演化的主要推动力。
2.具体几个使用关键技术
a.首先是apache的commonpool2 Jar包 其实也是缓存IO的一种方式
项目启动起来的时候,会static创建一个GenericKeyedObjectPool对象,然后将常用的ClientID放进去对象池初始化使用,方便后面服务调用时候每次发送前的处理。
往对象池中塞对象GenericKeyedObjectPool(属于apache.commonpool2包中的接口),这个对象池技术运用的范围就很广了。比如Jedis框架中使用的对象池缓存技术就是依赖的commonpool2 Jar包去实现的。
几个概念:
对象池(ObjectPool): 掌管对象的生命周期,获取,激活,验证,钝化,销毁等
池对象(PooledObject): 池化对象,是需要放到ObjectPool对象的一个包装类。添加了一些附加的信息,比如说状态信息,创建时间,激活时间,关闭时间等
池对象工厂(PooledObjectFactory): 用来创建池对象, 将不用的池对象进行钝化(passivateObject), 对要使用的池对象进行激活(activeObject), 对池对象进行验证(validateObject), 对有问题的池对象进行销毁(destroyObject)等工作
对象池化主要用于减少对象在创建和销毁上面的开销,如果是小对象则不需要池化,如果是大对象可以考虑池化,对于像数据库连接、网络之类的重对象来说是很有必要池化的,开发者自己根据需求判断,如果创建某种对象成为了影响程序性能的关键因素则需要池化。
关系图如下: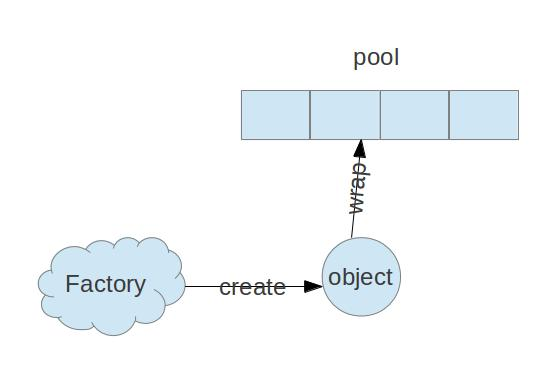
ObjectPool
1 | //从池中获取对象 |
PooledObject
1 | //获得目标对象 |
PooledObjectFactory
// 创建一个新对象;当对象池中的对象个数不足时,将会使用此方法来”输出”一个新的”对象”,并交付给对象池管理
PooledObject
// 销毁对象,如果对象池中检测到某个”对象”idle的时间超时,或者操作者向对象池”归还对象”时检测到”对象”已经无效,那么此时将会导致”对象销毁”;
// “销毁对象”的操作设计相差甚远,但是必须明确:当调用此方法时,”对象”的生命周期必须结束.如果object是线程,那么此时线程必须退出;
// 如果object是socket操作,那么此时socket必须关闭;如果object是文件流操作,那么此时”数据flush”且正常关闭.
void destroyObject(PooledObject
// 检测对象是否”有效”;Pool中不能保存无效的”对象”,因此”后台检测线程”会周期性的检测Pool中”对象”的有效性,如果对象无效则会导致此对象从Pool中移除,并destroy;
// 此外在调用者从Pool获取一个”对象”时,也会检测”对象”的有效性,确保不能讲”无效”的对象输出给调用者;
// 当调用者使用完毕将”对象归还”到Pool时,仍然会检测对象的有效性.所谓有效性,就是此”对象”的状态是否符合预期,是否可以对调用者直接使用;
// 如果对象是Socket,那么它的有效性就是socket的通道是否畅通/阻塞是否超时等.
boolean validateObject(PooledObject
// “激活”对象,当Pool中决定移除一个对象交付给调用者时额外的”激活”操作,比如可以在activateObject方法中”重置”参数列表让调用者使用时感觉像一个”新创建”的对象一样;如果object是一个线程,可以在”激活”操作中重置”线程中断标记”,或者让线程从阻塞中唤醒等;
// 如果object是一个socket,那么可以在”激活操作”中刷新通道,或者对socket进行链接重建(假如socket意外关闭)等.
void activateObject(PooledObject
// “钝化”对象,当调用者”归还对象”时,Pool将会”钝化对象”;钝化的言外之意,就是此”对象”暂且需要”休息”一下.
// 如果object是一个socket,那么可以passivateObject中清除buffer,将socket阻塞;如果object是一个线程,可以在”钝化”操作中将线程sleep或者将线程中的某个对象wait.需要注意的时,activateObject和passivateObject两个方法需要对应,避免死锁或者”对象”状态的混乱.
void passivateObject(PooledObject
实例
1 | private static final Logger LOGGER = LoggerFactory.getLogger(ConnectionTestFactory.class); |
Config详解
- lifo:连接池放池化对象方式,默认为true
true:放在空闲队列最前面
false:放在空闲队列最后面 - fairness:等待线程拿空闲连接的方式,默认为false
true:相当于等待线程是在先进先出去拿空闲连接 - maxWaitMillis:当连接池资源耗尽时,调用者最大阻塞的时间,超时将跑出异常。单位,毫秒数;默认为-1.表示永不超时. 默认值 -1
maxWait:commons-pool1中 - minEvictableIdleTimeMillis:连接空闲的最小时间,达到此值后空闲连接将可能会被移除。负值(-1)表示不移除;默认值1000L * 60L * 30L
- softMinEvictableIdleTimeMillis:连接空闲的最小时间,达到此值后空闲链接将会被移除,且保留“minIdle”个空闲连接数。负值(-1)表示不移除。默认值1000L * 60L * 30L
- numTestsPerEvictionRun:默认值 3
- evictionPolicyClassName:默认值org.apache.commons.pool2.impl.DefaultEvictionPolicy
- testOnCreate:默认值false
- testOnBorrow:向调用者输出“链接”资源时,是否检测是有有效,如果无效则从连接池中移除,并尝试获取继续获取。默认为false。建议保持默认值.
- testOnReturn:默认值false
- testWhileIdle:向调用者输出“链接”对象时,是否检测它的空闲超时;默认为false。如果“链接”空闲超时,将会被移除;建议保持默认值。默认值false
- timeBetweenEvictionRunsMillis:“空闲链接”检测线程,检测的周期,毫秒数。如果为负值,表示不运行“检测线程”。默认值 -1L
- blockWhenExhausted:默认值true
- jmxEnabled:默认值true
- jmxNamePrefix:默认值 pool
- jmxNameBase:默认值 null
- maxTotal:链接池中最大连接数,默认值8
commons-pool1 中maxActive改成maxTotal - maxIdle:连接池中最大空闲的连接数,默认为8
- minIdle: 连接池中最少空闲的连接数,默认为0
- softMinEvictableIdleTimeMillis: 连接空闲的最小时间,达到此值后空闲链接将会被移除,且保留“minIdle”个空闲连接数。默认为-1.
- numTestsPerEvictionRun: 对于“空闲链接”检测线程而言,每次检测的链接资源的个数。默认为3.
- whenExhaustedAction: 当“连接池”中active数量达到阀值时,即“链接”资源耗尽时,连接池需要采取的手段, 默认为1:
0:抛出异常
1:阻塞,直到有可用链接资源
2:强制创建新的链接资源
但是这里需要说明的是,对象池技术很容易成为系统IO的瓶颈。
ObjectPool
常見的幾個 ObjectPool 實現性能都很差,反而很容易成為性能瓶頸。 Stormpot 性能強悍,不過存在偶爾死鎖的問題,而且作者也停止維護了。 HikariCP 性能不錯,不過其本身是一款數據庫連接池,用作 ObjectPool 並不稱手。我的建議是儘量避免使用 ObjectPool,轉而使用替代技術。更重要的是 Netty 的 Channel 是線程安全的,並不需要使用 ObjectPool 來管理。只需要一個簡單的容器來存儲 Channel,用的時候使用 負載均衡策略 選出一個 Channel 出來就行了。
| framework | thrpt (ops/us) |
|---|---|
| ThreadLocal | 685.418 |
| Stormpot | 272.934 |
| HikariCP | 139.126 |
| SegmentLock | 19.415 |
| CommonsPool2 | 1.107 |
| CommonsPool | 0.276 |
